


お仕事おつにゃッス🐈文系未経験から社内SEになった、あっきょ(@daily_code_JP)です!
インターネット上で公開されているデータを自動で収集できると便利ですよね。
また、データをいちいちコピペする作業は面倒くさいですよね。
GASの機能を使えば1クリックでweb上のデータを自動で取得します。
この記事ではコピペOKのサンプルコードで解決します。
こんな人におすすめ!
- データ収集を自動化したい
- コピペする時間を減らして作業を楽にしたい
- JavaScriptを学んだけど何をつくればいいかわからない
誰でも無料で簡単にできますので気軽に学んでいきましょう!
サイト運営者

あっきょ
地方の中小企業で働く文系卒の総務&社内エンジニア。自身のプログラミング学習の経験から、未経験者でも挫折しないでスキルアップの支援をするサイト『デイコー』を運営。得意な言語:GAS・JavaScript・Python
GASでWEBスクレイピングするイメージ

GASでYahoo!ニュースの経済項目をスクレイピング。
コピペの繰り返すことなく、1クリックですべての作業が終わります。
今回は記事のタイトルのみを抽出してログ出力するようにします。
参考記事 : 経済ニュース – Yahoo!ニュース
スクレイピングとは?

スクレイピングとはWEB上に存在するデータを自動的に取り出して保存する技術。
競合調査や分析などの大規模にデータを処理するときに使用します。
データ収集から保存までの一連の作業を自動化すると手間と作業時間を大いに減らせます。
GASでは1クリックすれば簡単にデータを取り出して保存していきます。
関連記事 : Web スクレイピングとは?自社サイトが晒される脅威から対策まで解説 | SBテクノロジー (SBT)
スクレイピングで気を付けること
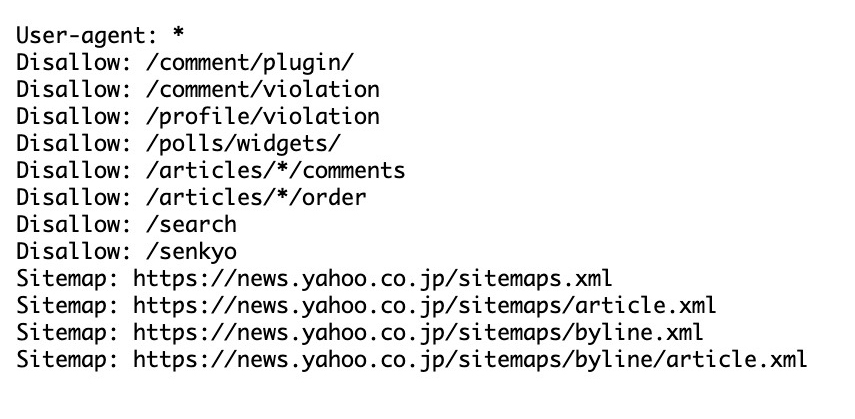
スクレイピングを行うには運営サイトが許可しているかを確かめる必要があります。
サーバーへの過度な負荷や抽出したデータの著作権侵害の可能性があるため<。
スクレイピングの許可は公開されているYahoo!のrobot.txtを確認します。
記事タイトルを得ること自体は問題なさそうですが、過度にスクレイピングするのは厳禁。
スクレイピングが原因で事件に発展!?

過度なスクレイピングで刑事事件になったことがあります。
2010年の岡崎市立中央図書館事件です。
利用者からサイトに接続できないと苦情が相次いでいましたが、とある男性が図書館の蔵書検索システムに自作のクローラを実行して図書情報を取得していたのが原因。
男性はサーバコンピューターの機能を停止させたとして業務妨害で逮捕されてしまいました。
GASの利用者は過度なスクレイピングをしないと信じていますが、便利だからといって使いすぎるのはご法度。
他社サービスに迷惑をかけず、robot.txtをしっかりと確認してからスクレイピングしましょう。
参考サイト : 岡崎市立中央図書館
参考記事 : 岡崎市立中央図書館事件 – Wikipedia
GASでWebスクレイピングをする準備
Google Apps Script で日本の株価を取得する準備をします。
ファイルは1つ必要です。
必要なファイル
- Google スプレッドシート…株式データの保存と株価のリアルタイム更新
サンプルコードを貼り付ける方法
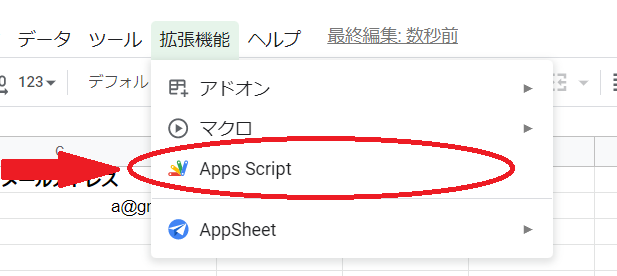
サンプルコードはGoogle スプレッドシートにコピペ。
上バーの「拡張機能」の中にある「Apps Script」をクリックしてコードを貼り付けます。
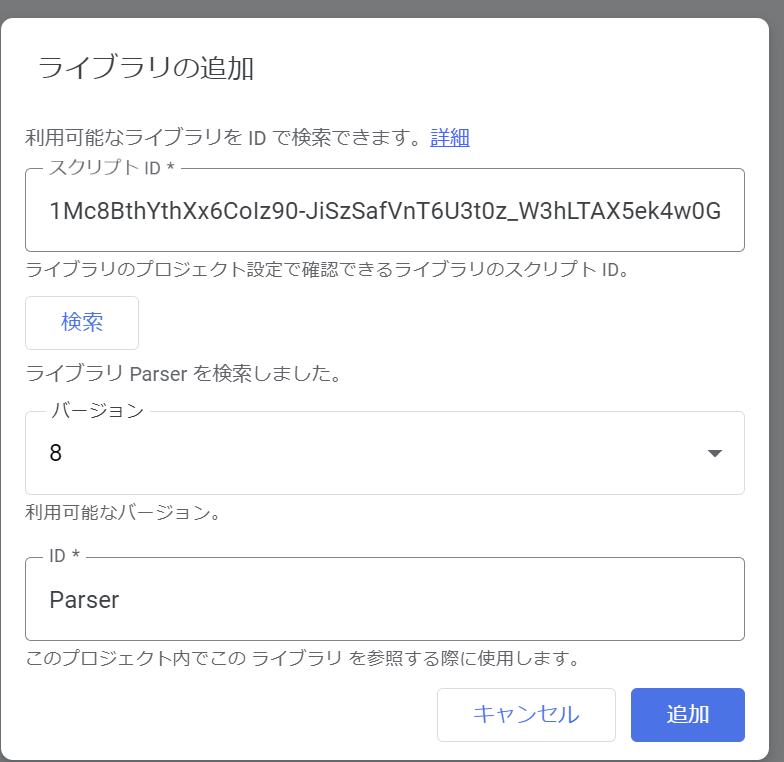
Parserライブラリの導入
GASでスクレイピングを行うには「Parserライブラリ」をダウンロードする必要があります。
コードを貼り付けるApps Scriptの左側にある「ライブラリ」をクリックします。
スクリプトIDに「1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw」と記入して検索ボタンをクリック。
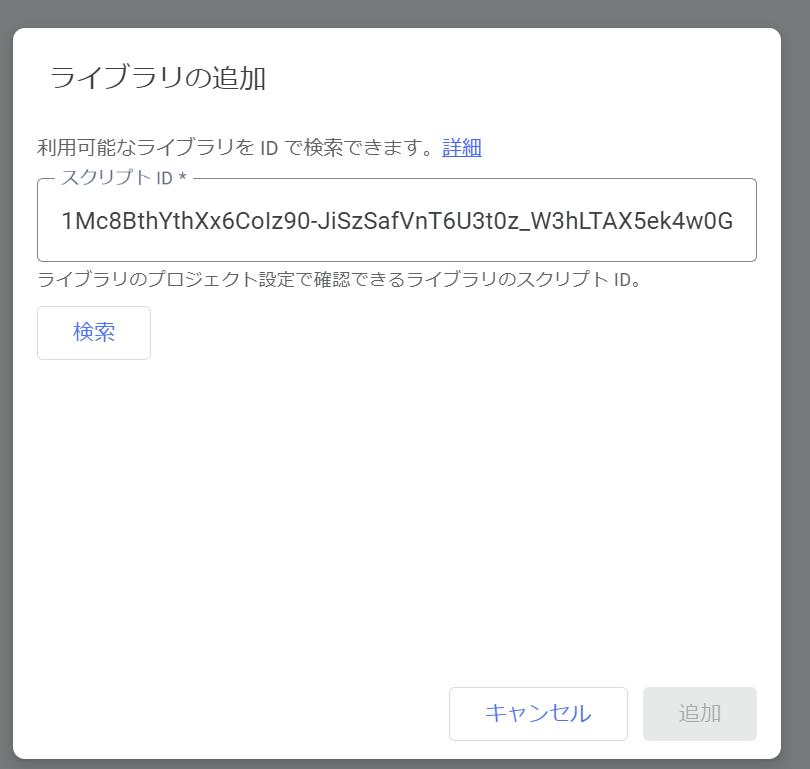
Parserのバージョン8を導入します。確認できたら、追加ボタンを押すと準備は完了です。
GASでWebスクレイピングするサンプルコード
GASでWebスクレイピングするサンプルコードを紹介していきます。
解説の項目
- サンプルコード
- buildメソッド と iterateメソッドの違い
- 【質問】コード内のdivやulは何?
サンプルコード
右上にあるマークを押すとコードのコピペが一瞬でできます。
この短いコードでスクレイピングできます。
function getNewsTitle(){
const url = "https://news.yahoo.co.jp/categories/business"; //スクレイピング先URL
const html = UrlFetchApp.fetch(url).getContentText(); //fetch通信でサイト内の文章を取得
const topicsDiv = Parser.data(html).from('<div class="sc-fhiYOA lmAaIt">') .to("</div>").build(); //ul要素を抽出
const topicsUl = Parser.data(topicsDiv).from('<ul>').to("</ul>").build(); //li要素を抽出
const topicsA = Parser.data(topicsUl).from('class="sc-btzYZH kitJFB"').to('>').iterate(); //記事タイトルを抽出
//取得した記事数ぶん、タイトルをログ出力
for(let i = 0; i < topicsA.length; i++){
//不必要な文字列を取り除いて記事タイトルを出力
Logger.log(topicsA[i].replace(/<span class="sc-bYSBpT kVZVlG"|>/g,"").replace('</a',""));
}
}buildメソッドとiterateメソッドの違い
サンプルコードでは記事タイトルを抽出するのに2つのメソッドを使用。
buildメソッドとiterateメソッドの違いは要素を抽出する範囲です。
| セッター名 | 詳細 |
|---|---|
| buildメソッド | 1番最初の要素のみを抽出 |
| iterateメソッド | 該当する要素をすべて抽出 |
文字だけではわからないので、以下のコードからli要素を抽出して違いを見ていきます。
function test(){
const html = '<ul class="season"><li>春</li><li>夏</li><li>秋</li><li>冬</li></ul>';
}buildメソッド
function test(){
const html = '<ul class="season"><li>春</li><li>夏</li><li>秋</li><li>冬</li></ul>';
const data = Parser.data(html).from('<li>').to('</li>').build();
Logger.log(data); //春を出力
}1番最初のli要素内にあった「春」のみを出力します。
つまり、先頭の要素だけを抽出します。
iterateメソッド
function test(){
const html = '<ul class="season"><li>春</li><li>夏</li><li>秋</li><li>冬</li></ul>';
const data = Parser.data(html).from('<li>').to('</li>').iterate();
Logger.log(data); //[春,夏,秋,冬]を出力
}ul要素内のli要素をすべて取得してその中の文字列をすべて抽出します。
抽出後にdataは配列に変換して格納します。
【質問】コード内のdivやulは何?

今回紹介したコードの中には「div」や「ul」などの文字が見られます。
これはHTML(HyperText Markup Language)というWebサイトを作成するために開発された言語でページ内の情報を構造化したもの。
スクレイピングでは、この構造化したHTMLを読み取ってタイトルを抽出しています。
 あっきょ
あっきょHTMLがわかれば、Yahoo!以外のサイトも自動でスクレイピングできるッスよ!
GASでWebスクレイピングするテスト
実際に、スプレッドシートで文字列を検索します。
Apps Scriptの上バーの文字が「getNewsTitle」になっていたら「実行」を押します。

「このアプリはGoogleで確認されていません」と表示した場合はこちら。

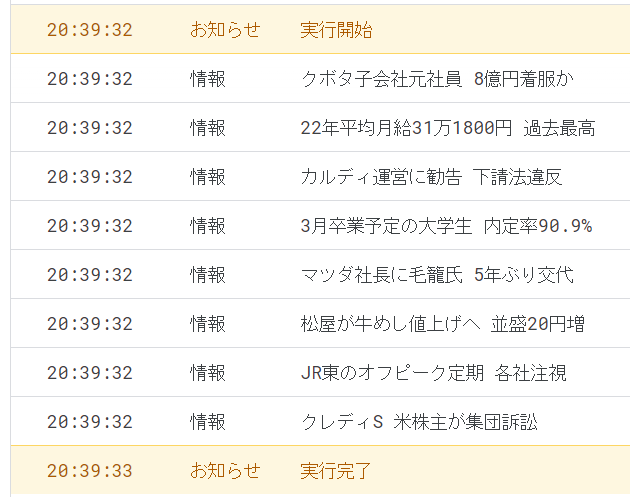
以下のようにログ出力されたら成功です。
ニュース記事のタイトルをすべて抽出できました。
【応用】取得したデータをスプシに記入する方法
応用で取得したデータをスプレッドシートに記入して保存できるようにします。
内容はほとんど変わりません。
コメントに「★」がついた2行を追加するだけで実現します。
function getNewsTitle(){
const sheet = SpreadsheetApp.getActiveSheet(); //★★アクティブ状態のシートを指定★★
const url = "https://news.yahoo.co.jp/categories/business"; //URL
const html = UrlFetchApp.fetch(url).getContentText(); //fetch通信でサイト内の文章を取得
const topicsDiv = Parser.data(html).from('<div class="sc-fhiYOA lmAaIt">') .to("</div>").build(); //ul要素を抽出
const topicsUl = Parser.data(topicsDiv).from('<ul>').to("</ul>").build(); //li要素を抽出
const topicsA = Parser.data(topicsUl).from('class="sc-btzYZH kitJFB"').to('>').iterate();
//取得した記事数ぶん、タイトルをログ出力
for(let i = 0; i < topicsA.length; i++){
//不必要な文字列を取り除いて記事タイトルを出力
const topic = topicsA[i].replace(/<span class="sc-bYSBpT kVZVlG"|>/g,"").replace('</a',"");
sheet.getRange(i+1, 1).setValue(topic); //★★i+1番目に文字列を記入★★
}
}実行結果は以下の通り。
Yahoo!ニュースの記事タイトルをスプレッドシートに保存できているのがわかります。

おわりに | GASで自動化のスキルを高めるには
以上がGoogle Apps ScriptでWebスクレイピングをする方法でした。
- スクレイピングすればweb上のデータの取得を1クリックでできる
- buildメソッドとiterateメソッドを使い分けるとよし
- 過度なスクレイピングは法的に問題があるので気をつけること
そのままコピペしたりデータ収集に使ったりしてみましょう。
GASで自動化のスキルを身につけるなら日々の学習と実践的なアプリ開発経験が必須。
GASを効率的に学ぶなら以下の2つの方法が多いです。
- 参考書やオンライン教材で独学
- プログラミングスクールを利用
正しく学ぶことで非エンジニアでも実用的な業務効率化のスキルが身に付きます。
デイコーでは、GASのサンプルコードからおすすめのプログラミングまで幅広く紹介。
初心者にもわかりやすく解説しています。




 あっきょ
あっきょプログラミングスクールは82社を分析したッス!
次回の記事もご期待ください!
それでは、よいプログラミングライフを!







